Chelsio iWARP RDMARemote DMA (RDMA) is a technology that achieves unprecedented levels of efficiency, thanks to direct system or application memory-to-memory communication, without CPU involvement or data copies. With RDMA enabled adapters, all packet and protocol processing required for communication is handled in hardware by the network adapter, for high performance. iWARP RDMA uses a hardware TCP/IP stack that runs in the adapter, completely bypassing the host software stack, thus eliminating any inefficiencies due to software processing. iWARP RDMA provides all the benefits of RDMA, including CPU bypass and zero-copy, while operating over standard Ethernet networks.
Chelsio’s Terminator 5 (T5) and Terminator 6 (T6) ASICs offer a high performance, robust implementation of RDMA (Remote Direct Memory Access) over 1/10/25/40/50/100Gb Ethernet – iWARP, a plug-and-play, scalable, congestion controlled and traffic managed fabric, with no special switch and configuration needed. T6 enables a unified wire for LAN, SAN and cluster applications, built upon a high bandwidth and low latency architecture along with a complete set of established networking, storage and cluster protocols operating over Ethernet (TCP, UDP, iSCSI, iSER, SMB3.x, iWARP, NVMe-oF, FCoE, NFS/Lustre over RDMA). Continuing on the performance curve established by previous generations of Terminator, T6 delivers sub-µsec latency to enable a high performance end-to-end RDMA solution that meets or exceeds the fastest FDR/EDR InfiniBand speeds in real‐world applications. The NVIDIA GPUDirectNVIDIA’s GPUDirect technology enables direct access to the Graphics Processing Unit (GPU) over the PCI bus, shortcutting the host system and allowing for high bandwidth, high message rate and low latency communication. When combined with Chelsio iWARP RDMA technology, high performance direct access to GPU processing units can be expanded seamlessly to Ethernet and Internet scales. With iWARP RDMA, network access to the GPU is achieved with both high performance and high efficiency. Since the host CPU and memory are completely bypassed, communication overheads and bottlenecks are eliminated, resulting in minimal impact on host resources, and translating to significantly higher overall cluster performance. | ||||
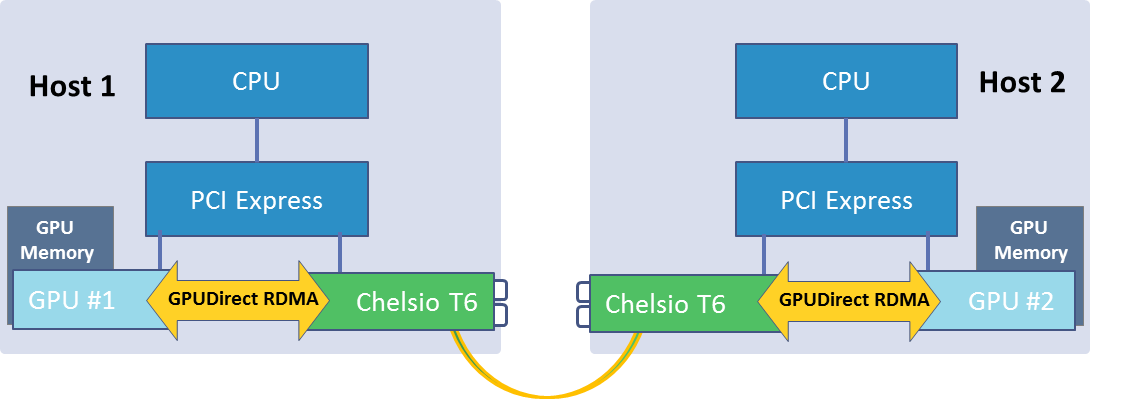
Figure 2 – GPUDirect with iWARP RDMA |
||||
| Benchmark results illustrate the benefits of GPUDirect RDMA using Chelsio’s T62100-LP-CR Unified Wire Ethernet adapter running at 100Gbps. Using GPUDirect RDMA results in a drastic reduction in latency for the test application. Latency reduction at such magnitude explains the benefits of RDMA and proves it to be a low latency and high performance fabric for GPUDirect. |


Resources
- GPUDirect RDMA over 40Gbps Ethernet (White paper)
- High-Performance GPU Clustering: GPUDirect RDMA over 40GbE iWARP (Chelsio and NVIDIA Webinar)
- Deployment of iWARP in GPU applications (Presentation at NVIDIA GTC 2016)
- GPU Direct RDMA with Chelsio iWARP (Video)